Find out how we built a serverless Data Lake in AWS using Go.
Building a serverless Data Lake in Go(lang)
Purpose
At KZN one of our primary specialties is cloud-native data engineering. Python is often our language of choice for this work, for a few good reasons:
- Lots of mature packages for ETL (awswrangler, pyspark)
- Fast to write
- Runs (relatively) quickly on Lambdas & Glue
- High rate of community adoption means open-source support is easy to come by
However on a recent pull request, a senior developer commented ‘Is Python actually the best tool for the job here?’. While it’s a simple question, it did make me think- just because everyone uses Python for data wrangling, is it actually the best solution? At KZN we are largely language agnostic, and if there is a compelling reason to use a different language or framework to solve a particular problem, then we are free to explore that. Go is a very popular up-and-coming language that gets a lot of attention (plus I recently read that it’s one of the fastest languages to run on Lambda), and so I asked the question-
Can I use Go to build a serverless data lake?
And if I can, how does the experience compare to the popular jock on the block- Python. I wanted to identify what the strengths and weaknesses are, what are the limitations etc.
KZN is a strong believer in not re-inventing the wheel, so the first thing I did was search. Has anyone already built a serverless data lake in Go?
I quickly came across lakeFS, which is a platform (written in Go) that is used to set up and manage a Data Lake. While what they have built looks like a very cool concept that we will have to test out in a seperate piece of work, there was a key condition that it did not satisfy: It’s not serverless.
For a lot of clients that we engage with, as well as internally, this does not fit with the value proposition of Cloud that we pitch. I’d like to stay consistent with what we preach, so I called this excuse enough to continue on with my experiment. The blog would also be a little lackluster if I ended it here.
That said, I need to make a quick disclosure- this is a Proof of Concept, not a refined product. For this blog we are going to leverage DynamoDB which isn’t often used in Data Lakes. We’re also going to do a bare minimum of actual data transformations. That’s because the focus of this piece of work is to explore Go’s general ability in handling data, not the ins and outs of its DataFrame library.
All code produced for this project is published open source.
What is a Data Lake?
Who knows. Tagging you in AWS.
Data Lake Design
It’s all well and good to build something, but things often pan out better if we first air out a clear idea of what we want to build and what we would like to achieve. The requirements I set myself for this project was:
- Carry data across at least three zones
- Utilise at least two different serverless platforms
- S3, DynamoDB, Redshift or Aurora RDS
If we’re building a data lake, we also need data. Radical critical thinking, I know. For this project I will be using a free open data set detailing Russian losses of equipment in the current Russia-Ukraine conflict.
For this project, data acquisition is out of scope. In the real world we would implement a lambda that reaches out to our source system and pulls data on a suitable schedule (or we would have a source system that extracts data directly to S3). I don’t have that much time, so I’m going to manually drop the CSV file into S3 and automate just the Data Lake portion of the work.
So, our basic data lake design will be:
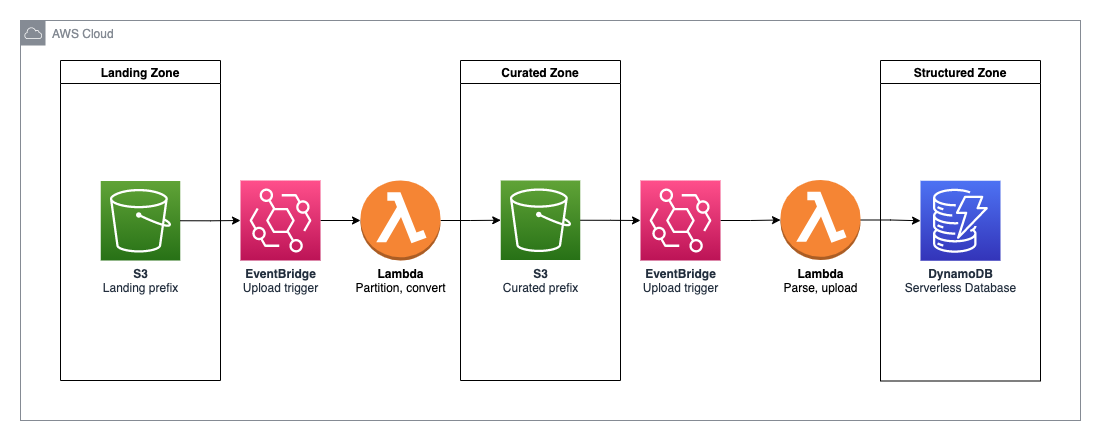
- Lets break this down step by step:
- Unstructured CSV data enters the data lake via manual upload to S3
- An EventBridge trigger watching that S3 folder triggers a Go Lambda function
- Lambda converts that file into a compressed parquet format and partitions it by date in the Curated Zone
- That upload to the Curated bucket triggers another EventBridge trigger which invokes another Go Lambda
- Lambda marshalls our data and writes it to DynamoDB
- Data is available for querying in DynamoDB
While quite simple, this hits a few classic use cases that we see internally and with our clients- multiple S3 zones, data partitioning, use of parquet for efficient storage and retrieval, and serverless databases.
Without further ado, let’s get started.
S3 Bucket Structure
First off I’m going to define the S3 bucket structure that all of our data will sit in. While you could create a bucket for each zone for greater data isolation, this is quite a small application so i’m going to create one bucket and define each zone as a sub-folder within that bucket. Our folder structure will look like:
s3://go-lake-bucket
- landing
- conflict-data
- curated
- conflict-data
- YYYY
- MM
- DD
- MM
- YYYY
- conflict-data
Looking at the structure of our bucket, there are a few things worth noting:
- The ‘Landing Zone’ is represented by files in the
s3://go-lake-bucket/landing/*path. - ‘Curated Zone’ is defined by files in the
s3://go-lake-bucket/curated/*path. - Data in the Curated zone is partitioned. If the same data file is uploaded twice on two seperate days, that file will be present twice in the Curated zone.
Partitioning the data in Curated allows us to have a full history of what was uploaded to the Data Lake and when. As files can be overwritten in Landing we can’t guarantee a full history of data there, so Curated is our archival point. Extra benefit is added here because our data in Curated is compressed and stored as parquet, which is a much more effective storage medium.
Creating our Data Lake resources
To create and deploy our AWS resources using Infrastructure as Code (IaC) and best practices, we are going to leverage the AWS Cloud Development Kit (CDK). This free software allows us to write high-level IaC and deploy it easily through the command line. All software written in this blog post is available in our public GitHub repo, called go-go-data-lake- a reference to a childhood TV show ‘Inspector Gadget’, who could summon any tool he needed by saying ‘go go …’.

The code showing all of the resources we create and how they hang together can be seen in our stack definition here. For the sake of this blog I’m only going to detail the Go-related components that took significant work to iron out. So, let’s quickly build and deploy a Go lambda function using CDK.
Ten hours of googling and coding later…
Easy. Lets take a look at what we have:
const convertLambda = new GoLambda(this, 'convert-lambda', {
sourceFolder: path.join(__dirname, '../src/convert'),
memorySize: 256,
timeout: Duration.minutes(1),
});
Wow! That’s so simple and easy to use. Is a high level construct like this really provided off the bat by AWS?
Absolutely not. That’s the result of two days of furious copy pasting off StackOverflow right there. Luckily for you, I’ve done the hard work so you don’t have to. From this blog post, we have published a highly reusable construct for you to create your own Golang lambdas, as easy as we have above. Check out the code you need to use right here. Use freely.
Looks hard. What does it do?
The GoLambda class is a very basic wrapper around the standard Lambda function provided by AWS. We accept the user parameters that are (usually) passed in, and set certain properties that need to be correct for Go to work on Lambdas.
What’s really going on behind the scenes is we instruct CDK to ‘bundle’ the application for us. This means doing a go build to construct an executable, then zipping it up and sending it to the cloud to be used as the execution root for our Lambda. Cross-compilation should succeed from any linux box as long as you have Docker installed.
OK but what about the actual Go code?
Converting CSV to Parquet with Go
The purpose of this lambda function is to:
- Read a
csvfile from the Landing bucket - Write that data to data to Curated in
parquetformat, partitioned by date
In our actual implementation, we can break these tasks down a little more:
- Download
csvfile from S3 to Lambda - Convert
csvto local parquet - Write local
parquetto S3
Downloading/Uploading to S3 using Golang
AWS publishes a Go package aws-sdk-go which is well documented and easy to use here. There are even sub-modules s3 and s3/s3manager that make life easier for us. Let’s take a look at the use case of downloading a file from S3:
func downloadS3(bucket string, key string) string {
file, err := os.Create("/tmp/file.csv")
if err != nil {
helper.Raise(err)
}
defer file.Close()
downloader := s3manager.NewDownloader(awsSession)
_, err = downloader.Download(file,
&s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
if err != nil {
helper.Raise(err)
}
log.Printf("%v downloaded to %v", key, file.Name())
return file.Name()
}
Most of what we see here is cleanup and error handling. AWS provided construct s3manager allows us to specify a locally open file, then a bucket & key to download and does the rest of the dirty work for us. This was the preferred solution as the package is built & maintained by AWS so we don’t have to worry about it becoming out of date or failing to support future versions. Uploading is done very similarly, except instead of instantiating a s3manager.NewDownloader, we create a s3manager.NewUploader. Crazy wacky syntax that couldn’t be guessed! If you want to see the full implementation for this file conversion, look here.
It’s worth noting the helper module that gets referenced here. This is a static helper class that I put together to clean up the main code file a bit. Almost definitely not the best way to structure this project, but I’m racing against the clock dammit.
File Conversion
The main package we leveraged for this was parquet-go. This is, by the way, one of the best documented and easy to understand packages i’ve ever worked with. Great README, dozens of real-world examples included in code.
For this example, I’m using variables and methods not set up here- for the full code see here.
parquet-go allows us write custom interfaces into parquet files, which is just awesome. Let me explain why. I can define the schema of the CSV i’m reading as:
type Row struct {
Name string
Age int32
}
When i’m then reading the CSV I can cast each row into an interface of that type:
for {
line, err := reader.Read()
if err == io.EOF {
break
}
row := Row{
Name: line[0],
Age: ParseInt32(line[1]),
}
}
So the current row has been converted into a Row type. Then, that object can be written to my parquet file using:
writer.Write(row)
Which is too good to be true! Literally. There’s a problem here. Let’s rewind a little.
Data lakes accept both structured and unstructured data. Generally as we move through zones, unstructured data becomes structured. A random CSV file dropped in S3 doesn’t have structure, but if we’re going to move it into a database (or a typed data format like parquet) then we need to provide it structure. And how is structure provided? Through metadata! In our use case, metadata is added to parquet files using metadata on the interface object. Which means our structure definition now becomes:
type Row struct {
Name string `parquet:"name=name, type=BYTE_ARRAY, convertedtype=UTF8"`
Age int32 `parquet:"name=age, type=INT32, convertedtype=INT_32"`
}
“But wait!”, you say, “I don’t know what values to put there!”
No worries, parquet-go documentation has you well and truly covered. If I can understand it, then you definitely can.
A quick point worth noting while we’re here- the AWS-published Python package aws-wrangler does auto-detection of data types, so if we were using Python here we wouldn’t have to manually specify any of this typing data!
The party continues - Integrating with DynamoDB
We now have structured data in the Curated zone. For the next step in our small, proof-of-concept data lake, I want to upload this data to DynamoDB. I’ve chosen Dynamo as it is serverless and represents a different storage medium that is quick and cheap to spin up in my limited time frame. I also want to test Go’s ability to integrate with more AWS services.
For this exercise, we will implement a Go Lambda that does the following:
- Read from a compressed parquet file in the Curated zone
- Write the results to DynamoDB
We are not doing any crazy or meaningful data science here- just experimenting with different storage mediums and how each service integrates with the Go SDKs. But, if we did want to do real data engineering here and apply filtering, joining etc, then I would apply gota, which is a DataFrame concept implemented in Go. It allows us to do a lot of the basic stuff that Pandas & PySpark does.
Cue more furious googling & coding
Great! That was far less painful than writing to parquet. Now that the structure to our data was already in the parquet, we didn’t have to worry too much about carrying typing data around. Luckily we could (pretty much) throw it straight up into DynamoDB. First lets look at the TypeScript CDK that defines our new Go function:
const dynamoLambda = new GoLambda(this, 'dynamo-lambda', {
sourceFolder: path.join(__dirname, '../src/dynamo'),
memorySize: 256,
timeout: Duration.minutes(1),
environment: {
TABLE_NAME: database.tableName
}
});
bucket.grantRead(dynamoLambda, 'curated/*');
database.grantWriteData(dynamoLambda);
Pretty simple right? Only major change here is that we pass in an environment variable, so we know which DynamoDB table we are writing into. Past that it’s standard permissions stuff- ability to read from the Curated zone and write to DynamoDB.
Boiled down, we read our parquet file using the same package we used to write it:
func readParquet(bucket string, key string) []Row {
localPath := downloadS3(bucket, key)
fr, err := local.NewLocalFileReader(localPath)
if err != nil {
Raise(err)
}
pq, err := reader.NewParquetReader(fr, new(Row), 1)
if err != nil {
Raise(err)
}
rowCount := int(pq.GetNumRows())
rows := make([]Row, rowCount)
if err = pq.Read(&rows); err != nil {
Raise(err)
}
return rows
}
Lets explain the code a little. First we download the parquet file to a local path. Then we open it for reading- just to provide an input buffer that can be fed into the ParquetReader. We point the ParquetReader at our buffer, and tell it we expect objects to have a structure of Row- the struct we defined at the top of our class.
On line 15 we create rows, which is initialised so the memory behind it is all reserved and set up for us. Then, we just read the data into rows. Really very simple thanks to all the great packages made available to us.
Now that we have an array of Row objects, we just need to PUT those items into DynamoDB:
func writeToDynamo(dynamo *dynamodb.DynamoDB, rows []Row) {
for _, row := range rows {
av, err := dynamodbattribute.MarshalMap(row)
if err != nil {
Raise(err)
}
input := &dynamodb.PutItemInput{
Item: av,
TableName: aws.String(tableName),
}
_, err = dynamo.PutItem(input)
if err != nil {
Raise(err)
}
}
}
This is, again, made easy thanks to some public examples that AWS has published. Using the public SDK we simply connect to Dynamo, then pass it our list of items and it handles the rest. We love others doing the hard work for us!
So once our code is deployed and tested, I head into the DynamoDB console to query our table and…
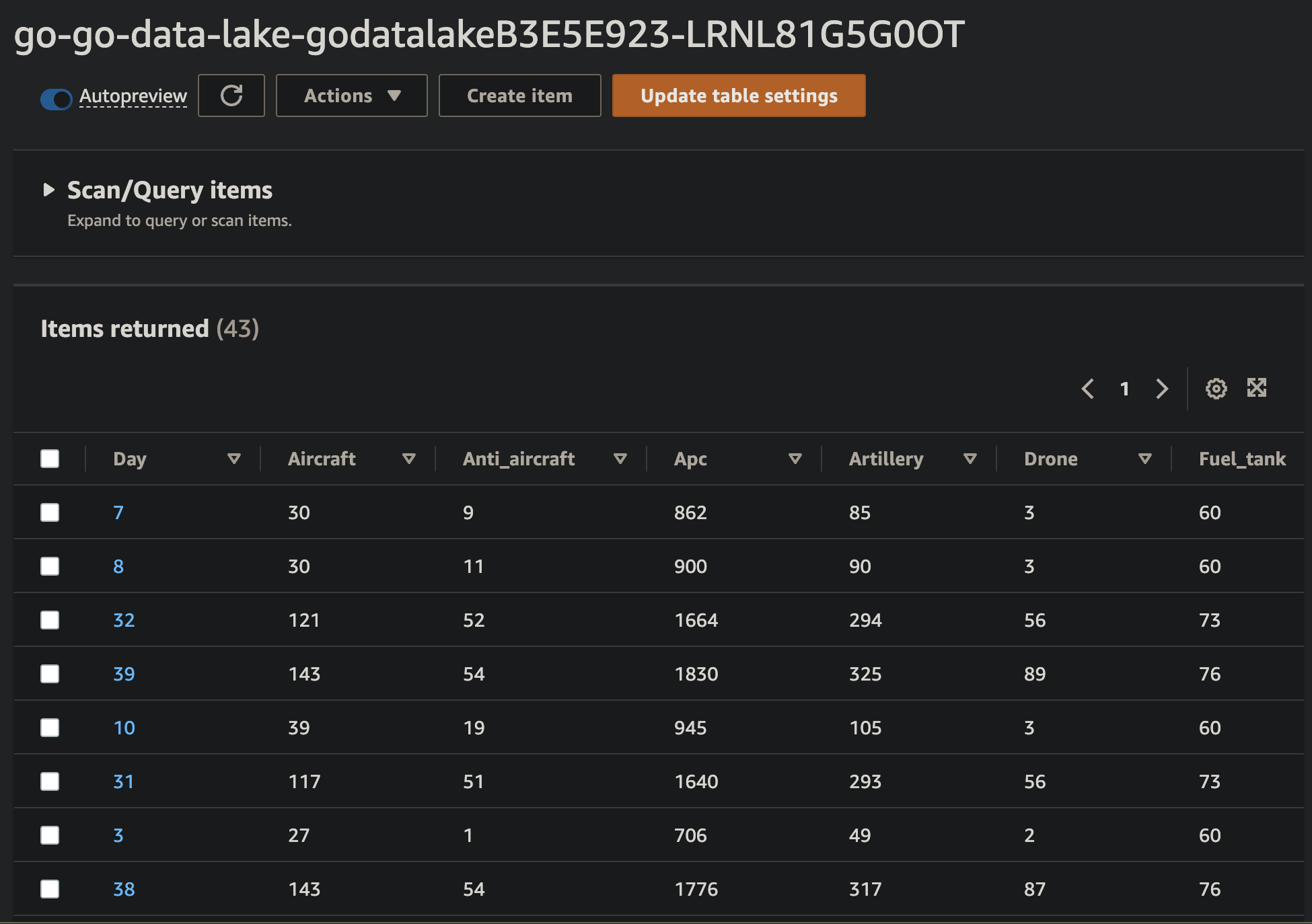
Voila! Our data has made it into the final zone of our POC data lake! Smells like success to me.
Conclusion
Basic data lakes (and data ponds) absolutely can be implemented in Go. There is a variety of community tooling to pick from, all of which is reasonably well developed and stable. We did not hit any blockers or unresolvable issues in this experiment, but we also didn’t do any gnarly data wrangling.
If used in a company-wide Data Lake that has to accept a wide variety of inputs and needs real calculations to be done, Go would probably be suited to solving some of your problems. Using it as your de-facto language will probably cost more time than it saves, but there are some smaller problems that would be very well suited to using Go.
Lessons Learnt
Strengths
- Both the quality and quantity of documentation. From the offical Go docs down to niche community packages that haven’t been touched in years, the documentation has been all around fantastic. Best of any community i’ve seen yet.
- Go is generally a nice language to write in. I like brackets and strong typing, so I much prefer to work in this language over Python. Very fast to learn as well.
- AWS Go SDK is actually pretty refined and built out. Didn’t come across anything it couldn’t do that I wanted it to.
Drawbacks
- CDK bundling of assets does not cache Go dependency downloads.. This was by far the biggest time waster I encountered. On running a
cdk synth, it could take up to 10 minutes for the Docker image to download all the Go dependencies doing ago build. Seriously painful when a Python synth takes ten seconds in comparison. I would love to see dependency caching implemented by CDK here. - I found importing modules locally very difficult and finicky. My understanding is Go purposely tries to make this difficult to encourage publishing proper modules. But in reality, I don’t want every module to get published, so some leniency would be appreciated.
- Little community support. Writing Lambdas in Go is still relatively niche, so if you’re looking to do something new there aren’t many resources out there to help you. This is not the case with Python.
- If you use the
GO1_Xruntime provided by AWS, the Lambda can only run on AMD processors. As ARM instances are 30% cheaper (and as Go runs fine on ARM…) it would be great for ARM to be supported. An alternative would be packaging a custom runtime. - Can’t use it on Glue. This isn’t something I mentioned much here, but Glue jobs are a core backbone to Data Lakes. A spark runtime on Go would be a total game changer. It looks like a few people have kind of made attempts at things similar to this.
Future Improvements
- Go, as a language, is more than capable of data wrangling. But for it to compare to its more popular sibling Python, it needs more community tooling. Some great things I would love to see that would greatly improve Go’s viability:
- A Go implementation of aws-data-wrangler
- Package that infers data types from open file buffers
- Ability to write/read straight to gota data frames
- Match file columns to interface fields automatically
- This would mean we don’t need to assign CSV row values directly to an object, name matching could be used to auto-populate your custom interface from a read CSV row