This is part 3 of a 3 part series
Part 3 - Automated Agent Login and other improvements
In our previous posts, we saw how we can work-around Amazon Connect’s lack of built-in voicemail functionality.
First, we found a way to let us record calls without involving a human agent. Our system is able to ask a caller to leave a message, then the recording of the call is dropped into an S3 bucket.
Part 2 showed how we could process the recording file with a lambda function to get useful details about the call and notify us via SNS.
In this post, we’ll discuss some issues with the implementation so far, and show some ways to further improve it.
Agent Availability
Although we’ve demonstrated a working voicemail solution, the whole thing depends on our voicemail agent answering calls for us. This is only possible when the agent is logged in and set as available within Amazon Connect’s Control Panel.
Using the methods we’ve shown so far, once the agent has taken its first voicemail call, the system will put it into an ‘After Call Work’ state. At this point, any new calls we try to transfer to the agent will be put on hold indefinitely until we take manual action to set the agent back to available.
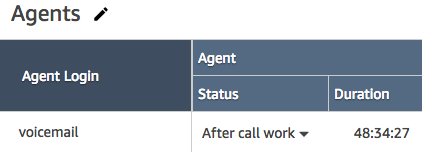
The easiest improvement we can make here is to change the ACW time-out setting for the voicemail user from 0 to 1 second:

Now whenever a voicemail message has been taken, the agent will be automatically made ready to take the next one instead of staying in an ACW state forever.
Agent session time-out
Eventually, our voicemail agent will end up back in ‘Offline’ mode. This seems to happen after a few days, perhaps when a session token has been expired within Amazon Connect. We’ve also seen the agent sometimes enter an ‘Error’ state when being transferred a call, but don’t know the cause of this yet.
We don’t want to have to babysit the agent’s availability state ourselves, so we’ll automate the process of logging it in and getting it ready to take messages. If we run this process periodically it will improve the availability of the system, unsurprisingly.
First, we tried using PhantomJS to automate the process, thinking it would be fairly easy to get running on lambda but hit some road-blocks.
Once logged in, the CCP’s client-side code failed to start due to PhantomJS lacking an implementation of browser audio drivers used to access the microphone. We also saw that the CCP application didn’t use any easy-to-replicate API calls, but instead uses a web-socket protocol to receive updates and issue commands. This gave us no choice but to persist with our goal of using the CCP application to manipulate the agent’s status.
But all was not lost. Not too long ago, Google has started releasing versions of Chrome that can be run completely headless, without displaying a graphical interface. What’s more, they’ve even released a high-level API https://github.com/GoogleChrome/puppeteer to make writing browser automation and testing scripts using it easier.
People have already managed to get these headless Chrome versions running in a lambda environment. I found this example Serverless project to be a great starting point: https://github.com/sambaiz/puppeteer-lambda-starter-kit
We can use Puppeteer navigate the CCP web interface, and use it to set our agent as available for calls.
Page navigation
You’ll usually start with getting puppeteer to load a web URL:
await page.goto(url, {waitUntil: 'domcontentloaded'});
Waiting for certain elements to appear can help us control navigation steps. For example, we have to wait for any authentication related redirections to occur, and for a form to be visible before we can fill it out:
await page.waitForSelector('input[type="username"]', {visible: true});
Filling Forms
To log in as the agent we need to find and fill out the login form fields, then submit the form:
await page.type('input[type="username"]', CCP_USERNAME);
await page.focus('input[type="password"]');
await page.keyboard.type(CCP_PASSWORD);
await page.keyboard.press('Enter');
Here we chose to submit the form by typing the ‘Enter’ key, as there wasn’t an actual form element on the page we could submit, and the CSS selectors needed to find the input fields seemed like they’d be less likely to change than ones to select the ‘Login’ button to click.
Inspecting page content
We needed to find out the agent’s current status to know whether to take any action to get them into an ‘available’ state. If we just made the script click buttons blindly, we could end up hanging up on a call in progress or setting the agent to be unavailable when they were already available.
const status = await page.$eval('.ccpState', (el) => {
return el.textContent;
});
Tying it all together
Putting all this together, we can run a lambda function triggered by a scheduled CloudWatch rule periodically to ensure our voicemail agent is ready to take messages. At the moment we run this daily towards the end of business hours, which is when we’ll need it to be available to take messages when we’re out of the office. Again, the Serverless Framework helps set up the scheduled rule easily with a 1-liner:
functions:
agentLogin:
handler: agent.login
description: "Logs into the CCP as the voicemail agent and ensures they're Available to take calls."
events:
- schedule: cron(0, 8, *, *, ?, *) # 4PM AWST daily
Additional safeguards
Since we can’t predict when Amazon Connect might decide to log our voicemail agent out again, we also wanted some extra safeguards in place to avoid having a caller be transferred to a queue that will never get answered.
Before transferring a call to voicemail, we use the ‘Check staffing’ function in our contact flow to see if the agent is available to take messages. If for some reason it isn’t, we invoke the lambda we discussed in the previous section. We actually had to add a second lambda function that sends an SNS to trigger the main one, since it takes longer to run than the allowed 8 seconds, and we wouldn’t want to block the phone call for that long anyway since you’d only hear a confusing 8 seconds of silence so callers might hang up before it reached the next step.
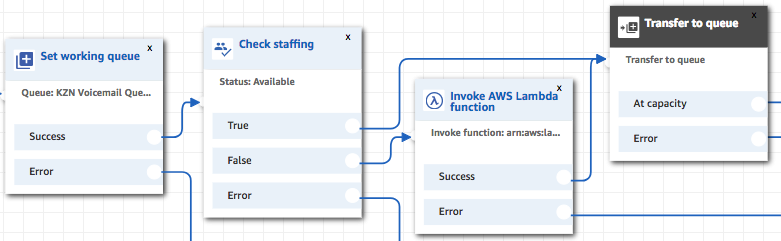
The agent-login process takes a while (around 45-60 seconds), or it might not happen at all if there was an unexpected issue. So to make sure a caller doesn’t get stuck on hold indefinitely, we set a time-out for the hold music in the ‘customer queue’ flow being used.

This should help prevent a caller being told we can take their message only to be stuck on hold or told we can’t actually take the message. A variation on this process might be to just ask the caller to call back later if the agent isn’t already available but still invoke the lambda to try and fix the agent to be ready next time.
Customer whisper flow
While testing the solution, we found that sometimes the whole ‘Please leave a message’ prompt can’t be heard, as the agent had already started saying it before the call was connected through to it.
This can be fixed by moving the prompt to a new ‘Whisper Flow’ which guarantees the prompt will be played in its entirety before the call is connected to the agent.
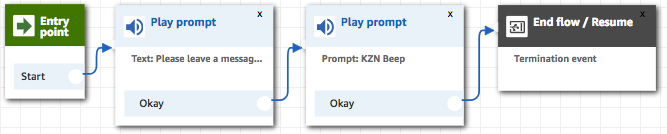
And setting it as the Customer Whisper Flow for the call prior to transferring it to the voicemail queue.

Potential Improvements
Hopefully, AWS will implement built-in voicemail at some point, or at least allow us to turn call recording on within contact flows (either all of them or just particular flows). Then we wouldn’t need to implement the complicated workaround of impersonating a human agent just to get it to record the call.
Until then, here are some more things we could do to improve the capability and reliability of the system.
Custom Agent Portal
At the moment, our agent login process is quite strongly coupled with the specific layout and styling of the Amazon Connect’s login pages and Control Panel interface. If AWS were to make any major changes to them our agent session would eventually time-out and our automated process would fail to get it logged in again. Although we could probably fix this pretty quickly if it happened, if we wanted to avoid the possibility as much as possible, we could implement our own control panel interface using the amazon-connect-streams SDK.
Unfortunately, it still pops up their own login form to authenticate, but that’s probably the part least likely to change and impact us since the input fields have standard names like ‘username’ and ‘password’.
This would allow us to write our own web interface which displays the agent’s current status and a button to change it to Available if needed. We would control the styling, so our Chrome automation scripting would be guaranteed to find things where it expects them. Alternatively, our control panel could just be a blank page with logic implemented on page load to check the agent status and change it to available using code from the SDK:
var routableState = agent.getAgentStates().filter(function(state) {
return state.type === AgentStateType.ROUTABLE;
})[0];
agent.setState(routableState, {
success: function() { ... },
failure: function() { ... }
});
Simultaneous voicemail messages
We’ve only set up one voicemail agent with automated processes to make it available to take messages. An agent can only answer one call at a time, so if two callers tried to leave a message at the same time one of them would get stuck in on hold until the first caller had finished leaving their message. If that first caller takes longer than the voicemail queue’s defined time-out, the second caller would be told they need to call back later.
To avoid this, we could set up a pool of voicemail agents to take the calls. We might need to pay for a phone number for each of them unless we’re able to set the same desk phone number on multiple agents.
Step Functions
If you’ve read through the lambda code from Part 2 of this blog post, you’d notice we do a lot of waiting for the Transcribe job to complete. Step functions would be a better way to handle this work-flow, but since we’re not expecting to handle thousands of voicemail messages, it wouldn’t actually save us much in service costs compared to the longer lambda execution time we have currently.
SES
Using SNS to notify us of new messages was a good first step, but this limits us to using plain text and having to provide a link to download the recording’s audio file.
Bringing Amazon’s Simple Email Service (SES) into the solution would let us format the messages using HTML, and perhaps even attach the recording to the email if we transcoded it to a compressed format first.
Summary
We hope you’ve found this series of posts useful. It might convince you to just use a 3rd party voicemail solution, but we were keen for the challenge of keeping the whole solution AWS native. It might not be 100% reliable, but it’s likely to be better than turning away callers completely as we’ve been doing prior to this.
We’ve published the full example here on GitHub - https://github.com/KZNGroup/serverless-connect-voicemail.